Материалы по тегу: pci express 5.0
|
20.08.2025 [11:13], Сергей Карасёв
SSSTC представила SSD серии CA8 — первые на рынке индустриальные M.2-накопители с памятью Kioxia BiCS Flash восьмого поколенияКомпания Solid State Storage Technology Corporation (SSSTC) анонсировала SSD семейства CA8, предназначенные для применения в интеллектуальных устройствах интернета вещей, платформах промышленной автоматизации, периферийных компьютерах, автомобильных системах и пр. По заявлениям SSSTC, изделия CA8 — это первые на рынке индустриальные устройства M.2 2280 с памятью Kioxia BiCS Flash восьмого поколения. Применены 218-слойные флеш-чипы 3D TLC NAND с технологией CBA (CMOS direct Bonded to Array), которая, как утверждается, существенно повышает энергоэффективность, производительность и плотность хранения данных по сравнению с решениями предыдущего поколения. 
Источник изображения: SSSTC В серию CA8 вошли модели вместимостью 512 Гбайт, а также 1, 2 и 4 Тбайт. Для подключения служит интерфейс PCIe 5.0 х4 (NVMe 2.0). Заявленная скорость последовательного чтения информации достигает 14 000 Мбайт/с, скорость последовательной записи — 12 000 Мбайт/с. Величина IOPS (операций ввода/вывода в секунду) составляет до 2 млн при произвольном чтении и 1,6 млн при произвольной записи: это, как подчеркивается, одни из самых высоких значений для индустриальных SSD, доступных на рынке. Диапазон рабочих температур простирается от 0 до +85 °C. Значение MTBF (средняя наработка на отказ) превышает 3 млн часов. Упомянута поддержка AES-256 и TCG Opal. Функция Power Loss Notification (PLN) предотвращает повреждение данных при неожиданных отключениях питания. Накопители способны выдерживать более одной полной перезаписи в сутки (1 DWPD) на протяжении пяти лет.
12.08.2025 [14:51], Владимир Мироненко
NVIDIA анонсировала компактные ускорители RTX PRO 4000 Blackwell SFF Edition и RTX PRO 2000 BlackwellNVIDIA объявила о предстоящем выходе GPU NVIDIA RTX PRO 4000 Blackwell SFF Edition и NVIDIA RTX PRO 2000 Blackwell, «воплощающих мощь архитектуры NVIDIA Blackwell в компактном и энергоэффективном форм-факторе», которые «обеспечат ИИ-ускорение для профессиональных рабочих процессов в различных отраслях». Новинки отличаются вдвое меньшими размерами по сравнению с традиционными GPU, и при этом оснащены RT-ядрами четвёртого поколения и тензорными ядрами пятого поколения с пониженным энергопотреблением. Как сообщает NVIDIA, новые ускорители разработаны для обеспечения производительности нового поколения для различных профессиональных рабочих процессов, обеспечивая «невероятное» ускорение процессов проектирования, дизайна, создания контента, ИИ и 3D-визуализации. По сравнению с ускорителем предыдущего поколения RTX A4000 SFF, модель RTX PRO 4000 SFF обеспечивает до 2,5 раза более высокую производительность в обработке ИИ-нагрузок и в 1,5 раза более высокую пропускную способность памяти, обеспечивая большую эффективность при том же максимальном энергопотреблении 70 Вт. 
Источник изображений: NVIDIA Ускоритель включает 8960 ядер NVIDIA CUDA, 24 Гбайт памяти GDDR7 ECC со 192-бит шиной и пропускной способностью 432 Гбайт/с. Используется интерфейс PCIe 5.0 x8. ИИ-производительность составляет 770 TOPS, RT-ядер — 73 TOPS, в формате FP32 — 24 TOPS. Доступно 2 движка NVENC девятого поколения и 2 движка NVDEC шестого поколения. Есть 4 разъёма DisplayPort 2.1b. Оптимизированная для массового проектирования и рабочих ИИ-процессов, RTX PRO 2000 обеспечивает до 1,6 раза более быстрое 3D-моделирование, в 1,4 раза более высокую производительность систем автоматизированного проектирования (САПР) и в 1,6 раза более высокую скорость рендеринга по сравнению с предыдущим поколением. Компания отметила, что инженеры САПР, продуктовые инженеры и специалисты творческих профессий по достоинству оценят 1,4-кратный прирост производительности RTX PRO 2000 при генерации изображений и 2,3-кратный прирост производительности при генерации текста, что обеспечивает более быструю итерацию, быстрое прототипирование и бесперебойную совместную работу.  RTX PRO 2000 оснащена 4352 ядрами NVIDIA CUDA, 16 Гбайт памяти GDDR7 ECC со 128-бит шиной и пропускной способностью 288 Гбайт/с. Используется интерфейс PCIe 5.0 x8. ИИ-производительность составляет 545 TOPS, RT-ядер — 54 TOPS, в формате FP32 — 17 TOPS. Доступно по одному движку NVENC девятого поколения и NVDEC шестого поколения. Есть 4 разъёма DisplayPort 2.1b. NVIDIA сообщила, что ускорители NVIDIA RTX PRO 2000 Blackwell и NVIDIA RTX PRO 4000 Blackwell SFF Edition поступят в продажу позже в этом году, не указав конкретные сроки.
12.08.2025 [11:39], Сергей Карасёв
InnoGrit выпустила SSD N3X со сверхнизкой задержкой для ИИ-системКомпания InnoGrit официально представила SSD семейства N3X для ИИ-платформ и периферийных вычислений. Устройства, обладающие повышенной надёжностью, доступны в вариантах вместимостью 800 Гбайт, а также 1,6 и 3,2 Тбайт. О подготовке накопителей InnoGrit-N3X сообщалось в конце мая текущего года. Тогда говорилось, что устройства оснащены контроллером InnoGrit Tacoma IG5669 и чипами памяти Kioxia XL-Flash второго поколения, функционирующими в режиме SLC. Применяется интерфейс PCIe 5.0 x4 (NVMe 2.0). По новой информации, задействован контроллер InnoGrit IG5668. Изделия обладают сверхнизкой задержкой: 13 мкс при чтении и 4 мкс при записи. Показатель при чтении, как утверждается, на 75 % ниже по сравнению со стандартными твердотельными накопителями с интерфейсом PCIe 5.0. Заявленная скорость последовательного чтения достигает 14 Гбайт/с, скорость последовательной записи — 12 Гбайт/с. Показатель IOPS (операций ввода/вывода в секунду) составляет до 1,6 млн при произвольной записи блоков данных по 4 Кбайт — это примерно в четыре раза выше, чем у типичных решений PCIe 5.0 для ЦОД. 
Источник изображения: InnoGrit SSD серии InnoGrit-N3X способны выдерживать до 100 полных перезаписей в сутки (100 DWPD): благодаря этому они подходят для использования в составе систем с высокой интенсивностью обмена данными. Реализованы средства сквозной защиты информации и шифрование по алгоритму AES-256. Функция Power Loss Protection (PLP) отвечает за сохранность данных при внезапном отключении питания. Устройства выпускаются в двух форм-факторах — U.2 и E1.S.
10.08.2025 [15:24], Сергей Карасёв
Silicon Motion продемонстрировала решения с SSD на основе контроллера MonTitan SM8366Компания Silicon Motion показала ряд продуктов, оснащённых высокопроизводительными SSD на базе контроллера MonTitan SM8366. Решение MonTitan SM8366 ориентировано на накопители для дата-центров и инфраструктур гиперскейлеров. Обеспечивается поддержка PCIe 5.0 x4, NVMe 2.0a и OCP 2.0. Доступны 16 независимых каналов NAND Flash, а заявленная производительность достигает 2400 MT/s. Скорость последовательной передачи данных может превышать 14,2 Гбайт/с, величина IOPS — 3,5 млн при работе с блоками данных по 4 Кбайт. Возможно создание накопителей в форматах E1.S, E1.L, U.2/3. Поддерживается память DDR4-3200 и DDR5-4800 в одно- и двухканальном режимах. Контроллер выполнен в корпусе FCBGA с размерами 21 × 21 мм.  В рамках FMS 2025 продемонстрирована система VAST Data Ceres V2 Dbox, оснащённая накопителями Unigen семейства Cheetah с контроллером MonTitan SM8366. Это, в частности, SSD формата E1.L вместимостью 128 Тбайт на чипах QLC NAND, а также изделия стандарта U.2 ёмкостью 3,2 Тбайт с чипами SLC NAND. Система VAST Data Ceres V2 Dbox выполнена в форм-факторе 1U и наделена DPU NVIDIA BlueField-3. 
Источник изображения: Silicon Motion Кроме того, показан сервер небольшой глубины Aetina AEX-2UA1 для периферийных вычислений, в состав которого включены накопители Innodisk 5TS-P на основе MonTitan SM8366. Система построена на модульной платформе NVIDIA MGX. Отмечается, что сервер Aetina AEX-2UA1 предоставляет ИИ-возможности в средах с ограниченным пространством для установки оборудования.
09.08.2025 [13:19], Сергей Карасёв
Беспортовый контроллер: Microchip представила RAID-ускорители Adaptec SmartRAID 4300 для NVMe-хранилищКомпания Microchip Technology анонсировала ускорители Adaptec SmartRAID 4300 для дата-центров, поддерживающих ресурсоёмкие нагрузки, в том числе связанные с ИИ. Решения предназначены для работы с массивами NVMe RAID в составе программно-определяемых хранилищ (SDS). Концепция Adaptec SmartRAID 4300 предполагает разделение платформы Microchip Smart Storage на программные и аппаратные компоненты. В данном случае CPU отвечает за непосредственную запись данных на твердотельные накопители, полноценно используя скоростные возможности интерфейса PCIe. Вместе с тем дополнительные расчёты (в том числе XOR-операции) переносятся с хост-процессора на RAID-ускоритель. Такой подход, как утверждается, устраняет узкие места, присущие традиционным решениям с последовательным подключением. В результате, достигается высокий уровень гибкости и масштабируемости. Возможно подключение до 32 устройств NVMe SSD с интерфейсом PCIe 4.0 х4 или PCIe 5.0 х4. По оценкам Microchip, изделия Adaptec SmartRAID 4300 обеспечивают семикратное увеличение производительности ввода-вывода (I/O) по сравнению с решениями предыдущего поколения. 
Источник изображений: Microchip В частности, в средах Windows показатель IOPS в режимах RAID 0 и RAID 5 достигает 5 млн при произвольном чтении данных блоками по 4 Кбайт и соответственно 4,8 млн и 2,3 млн при произвольной записи. Скорость последовательного чтения составляет до 317 Гбайт/с (RAID 0) и 291 Гбайт/с (RAID 5), скорость последовательной записи — до 120 Гбайт/с (RAID 0) и 26 Гбайт/с (RAID 5). При работе с Linux скорости значительно выше. Так, величина IOPS в режимах RAID 0 и RAID 5 при произвольном чтении достигает 27,2 млн и 27,3 млн соответственно, при произвольной записи — 22,4 млн и 5,1 млн. Скорость последовательного чтения — до 300 и 291 Гбайт/с, последовательной записи — до 196 и 155 Гбайт/с. 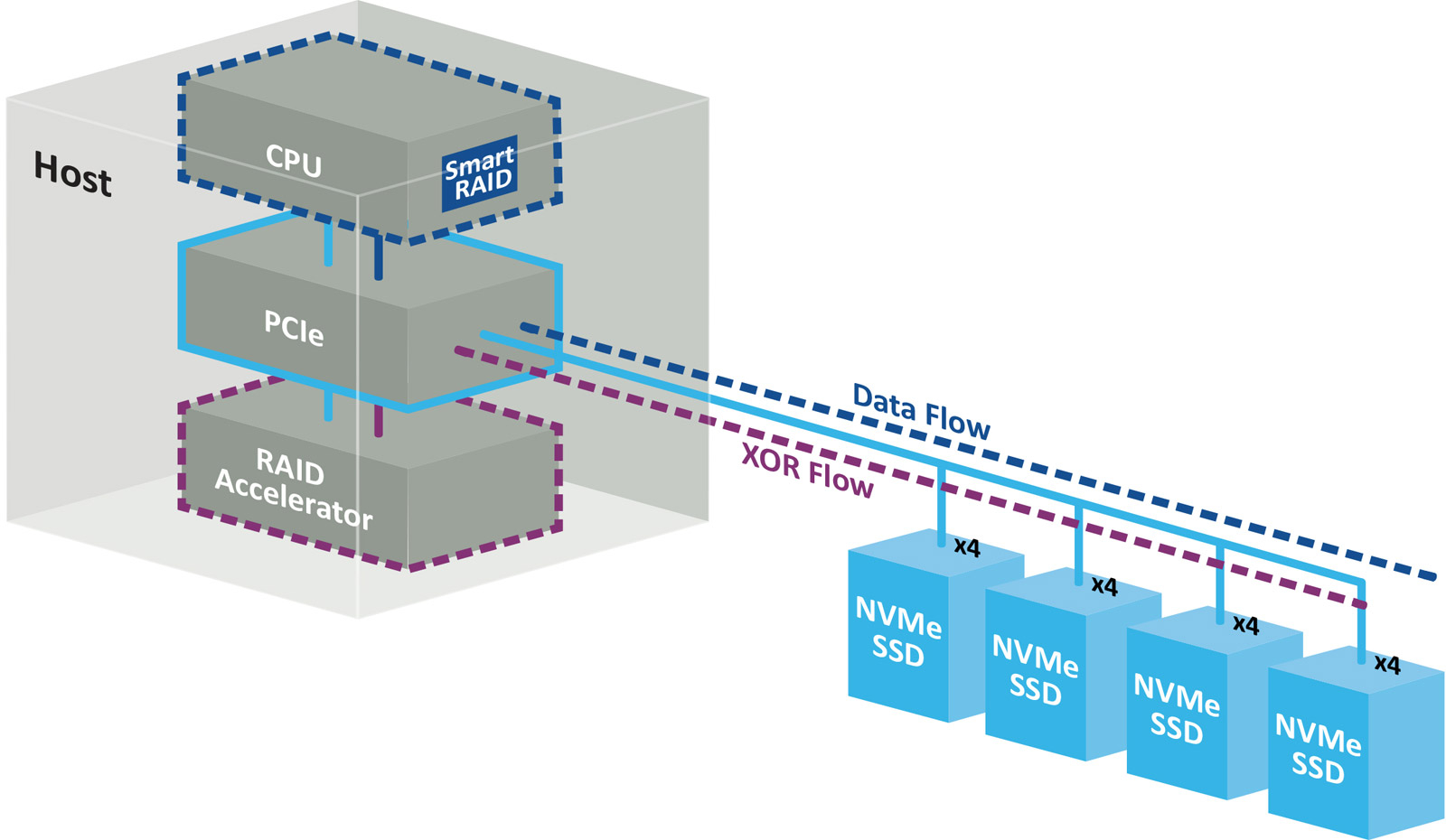 Ускорители выполнены в виде низкопрофильной (HHHL) карты расширения с интерфейсом PCIe 4.0 х16. Поддерживаются массивы RAID 0/1/5/10/50. Габариты составляют 68,9 × 167,65 мм. Значение MTBF (средняя наработка на отказ) — до 3 млн часов при температуре до +40 °C. Гарантирована совместимость с Windows Server, Red Hat Enterprise Linux, SuSE Linux Enterprise Server, Oracle Linux.
06.08.2025 [00:28], Владимир Мироненко
Sandisk анонсировала NVMe SSD ёмкостью 256 Тбайт, созданный специально для ИИ-системКомпания SanDisk анонсировала NVMe SSD UltraQLC SN670 объёмом до 256 Тбайт, разработанный для удовлетворения растущих потребностей в ИИ-системах и ресурсоёмких вычислениях. Новинка позиционируется как решение для крупномасштабных приложений — таких, как озёра данных ИИ, высокоскоростной приём данных и аналитика в реальном времени, — где требуется масштабный и быстрый доступ к информации. А в скором времени компания обещает создать накопитель ёмкостью 1 Пбайт. Созданный на недавно анонсированной платформе UltraQLC, твердотельный накопитель SanDisk UltraQLC SN670 будет доступен в вариантах ёмкостью 256 и 128 Тбайт. В нём используется 218-слойная 3D NAND-память BiCS с кристаллом CBA (CMOS Direct Bonded to Array) объёмом 2 Тбит и контроллер с интерфейсом PCIe 5.0. Аналогичные чипы флеш-памяти BiCS FLASH QLC 3D с технологией CBA установлены в 245,76-Тбайт SSD компании Kioxia, производственного партнёра SanDisk. 
Источник изображения: SanDisk Используемая в SanDisk UltraQLC SN670 технология Direct Write QLC, позволяет обходиться без традиционной буферизации SLC, осуществляя безопасную запись непосредственно на слои QLC без потерь при отключении питания. Как отметил ресурс Blocks & Files, обычно это приводит к снижению производительности по сравнению с аналогичными накопителями, использующими кеш SLC, если только не используются дополнительные усовершенствования для ускорения процесса. Функция динамического масштабирования частоты (Dynamic Frequency Scaling) обеспечивает рост производительности до 10 % при заданном уровне энергопотребления. Для поддержания пропускной способности и долговечности при экстремальных объёмах записи в SN670 используется масштабируемый многоядерный контроллер. Обновлённый профиль Data Retention (DR) позволяет сократить число циклов обновления данных на 33 %, что повышает надёжность накопителя и снижает энергопотребление. Обе версии накопителя SanDisk UltraQLC SN670 объёмом 128 и 256 Тбайт поступят в продажу в форм-факторе U.2 в I половине 2026 года. Ожидается, что в течение года появятся и другие форм-факторы. Если SN670 будет готов к апрелю 2026 года, это, по мнению Blocks & Files, означает, что на доработку накопителя потребуется ещё около восьми месяцев. Вероятно, именно поэтому компания пока не раскрывает информацию о производительности и надёжности — накопитель и контроллер, по всей видимости, ещё не прошли финальное тестирование.
03.08.2025 [12:14], Сергей Карасёв
Enfabrica представила технологию EMFASYS для расширения памяти ИИ-системКомпания Enfabrica анонсировала технологию EMFASYS, которая объединяет Ethernet RDMA и CXL для создания пулов памяти, предназначенных для работы с серверными ИИ-стойками на базе GPU. Решение позволяет снизить нагрузку на HBM-память ИИ-ускорителей и тем самым повысить эффективность работы всей системы в целом. Enfabrica основана в 2019 году. Стартап предлагает CXL-платформу ACF на базе ASIC собственной разработки, которая позволяет напрямую подключать друг к другу любую комбинацию GPU, CPU, DDR5 CXL и SSD, а также предоставляет 800GbE-интерконнект. Компания создала чип ACF SuperNIC (ACF-S) для построения высокоскоростного интерконнекта в составе кластеров ИИ на основе GPU. В рамках платформы EMFASYS специализированный пул памяти подключается к GPU-серверам через чип-коммутатор ACF-S с пропускной способностью 3,2 Тбит/с, который объединяет PCIe/CXL и Ethernet. Поддерживаются интерфейсы 100/400/800GbE, 32 сетевых порта и 160 линий PCIe. Могут быть задействованы до 144 линий CXL 2.0, что позволяет использовать до 18 Тбайт памяти DDR5 (в перспективе — до 28 Тбайт). Вместо копирования и перемещения данных между несколькими чипами на плате Enfabrica использует один SuperNIC, который позволяет представлять память в качестве целевого RDMA-устройства для приложений ИИ. 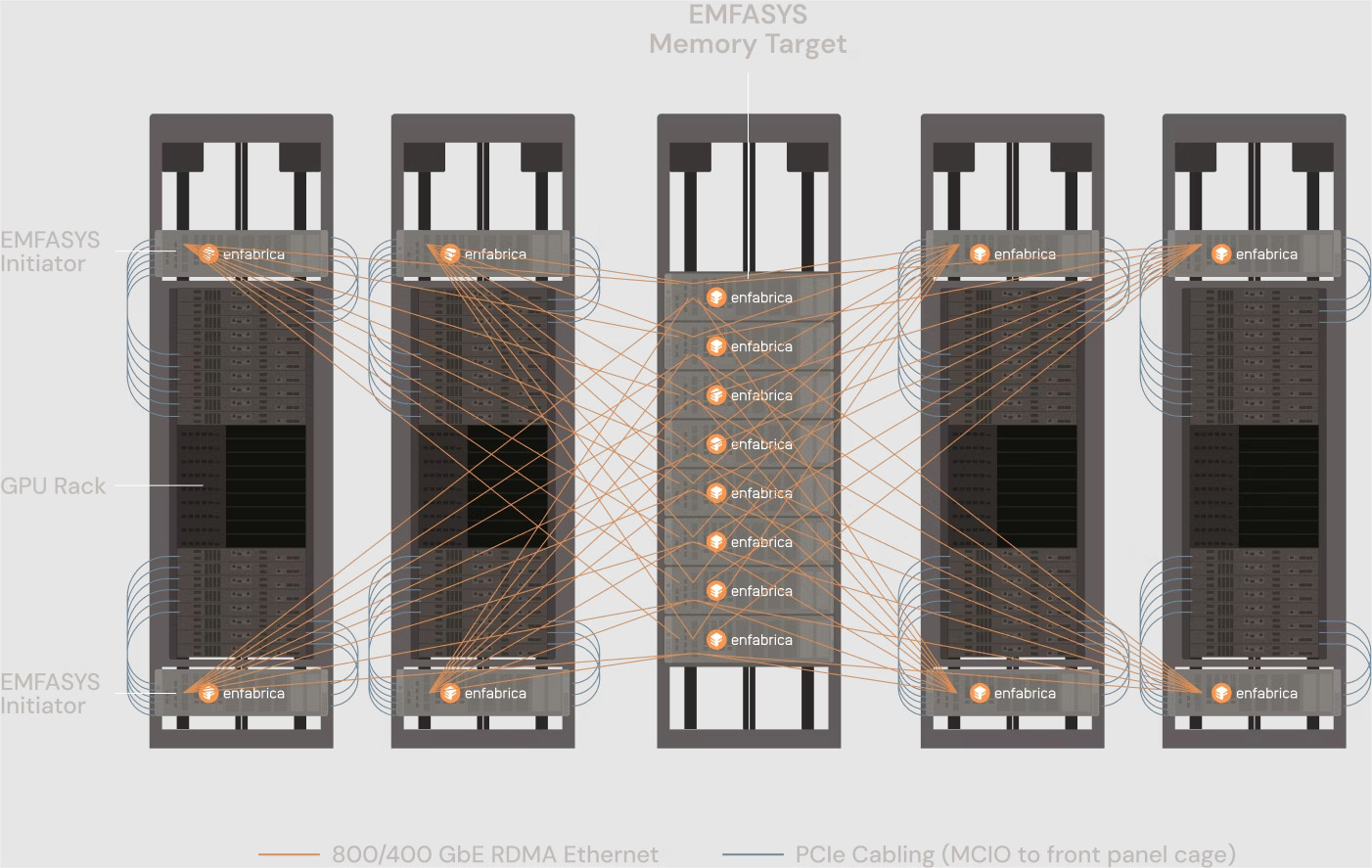
Источник изображений: Enfabrica Высокая пропускная способность памяти достигается за счёт распределения операций более чем по 18 каналам на систему. Время доступа при чтении измеряется в микросекундах. Программный стек на базе InfiniBand Verbs обеспечивает массовую параллельную передачу данных с агрегированной полосой пропускания между GPU-серверами и памятью DRAM через группы сетевых портов 400/800GbE. 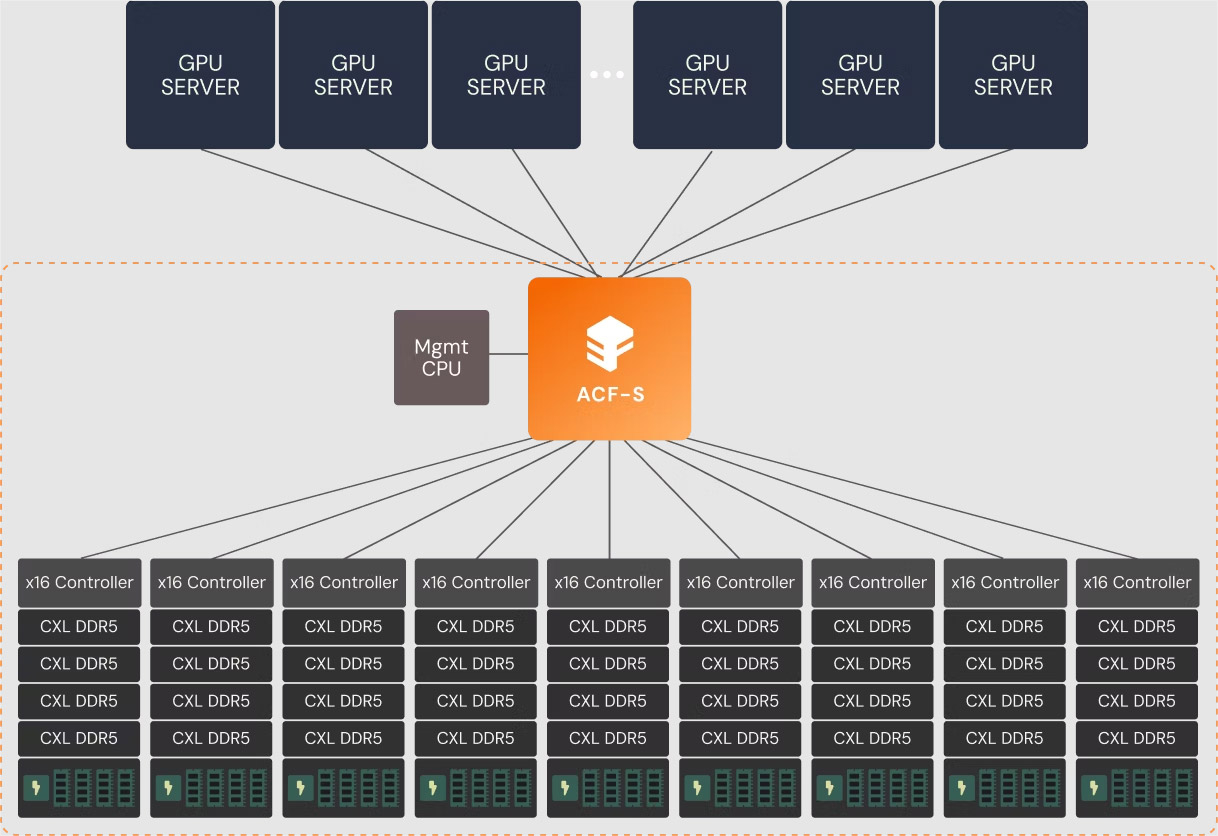 Enfabrica отмечает, что рабочие нагрузки генеративного, агентного и рассуждающего ИИ растут экспоненциально. Во многих случаях таким приложениям требуется в 10–100 раз больше вычислительной мощности на запрос, чем большим языковым моделям (LLM) предыдущего поколения. Если память HBM постоянно загружена, дорогостоящие ускорители простаивают. Технология EMFASYS позволяет решить проблему посредством расширения памяти: в этом случае ресурсы GPU используются более полно, а заявленная экономия достигает 50 % в расчёте на токен на одного пользователя.
30.07.2025 [11:40], Сергей Карасёв
Micron представила новые SSD для дата-центров: PCIe 6.0, до 28 Гбайт/с и до 122,88 ТбайтКомпания Micron Technology анонсировала SSD серий 6600 ION, 7600 и 9650 для дата-центров и систем корпоративного класса. Новинки, подходящие в том числе для ресурсоёмких нагрузок ИИ, предлагаются в различных форм-факторах — U.2, E1.S и E3.S. Изделия Micron 6600 ION оптимизированы для сред, в которых постоянно генерируются и обрабатываются большие массивы данных: это может быть, например, инфраструктура интернета вещей (IoT). Устройства выполнены на основе флеш-чипов G9 QLC NAND, а для обмена данными задействован интерфейс PCIe 5.0 x4 (NVMe 2.0d). Доступны исполнения E3.S 1T и U.2. В семейство Micron 6600 ION входят модификации вместимостью 30,72, 61,44 и 122,88 Тбайт. В I половине 2026 года появится вариант ёмкостью 245 Тбайт. Скорость последовательного чтения информации достигает 14 000 Мбайт/с, скорость последовательной записи — 3000 Мбайт/с. Показатель IOPS при произвольном чтении блоков данных по 4 Кбайт составляет до 2 млн, при произвольной записи — до 100 тыс. Показатель надёжности достигает 1 DWPD (полная перезапись в сутки) при последовательном доступе и от 0,075 до 0,3 DWPD при случайном доступе. 
Источник изображений: Micron Накопители серии Micron 7600, в свою очередь, подходят для задач ИИ. Устройства выпускаются в форматах U.2 (15 мм), E1.S (9,5 и 15 мм) и E3.S 1T (15 мм). Применены чипы флеш-памяти G9 TLC NAND и интерфейс PCIe 5.0 x4 (NVMe 2.0d). Скорость последовательных чтения и записи — до 12 000 и 7000 Мбайт/с соответственно. 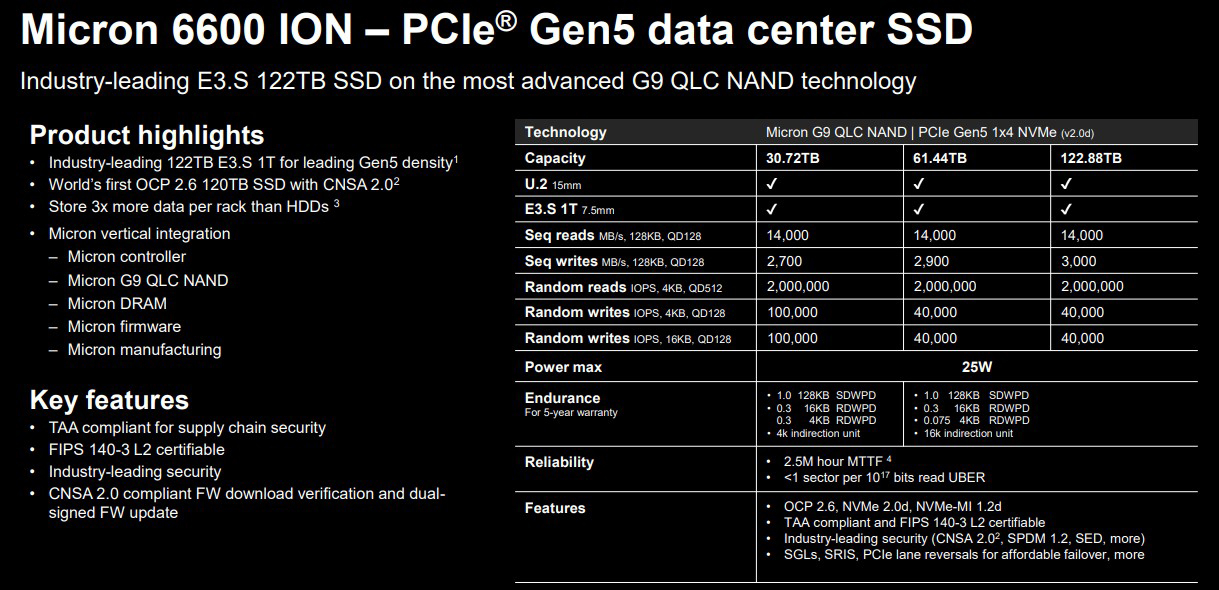 Покупатели смогут выбирать между модификациями Micron 7600 Pro и Micron 7600 Max. В первом случае вместимость варьируется от 1,92 до 15,36 Тбайт, а надёжность находится на уровне 1 DWPD (на протяжении пяти лет). Величина IOPS — до 2,1 млн при чтении и до 400 тыс. при записи. В случае Micron 7600 Max ёмкость составляет от 1,6 до 12,8 Тбайт, показатель DWPD равен 3. Значение IOPS — до 2,1 млн при произвольном чтении и до 675 тыс. при произвольной записи. Micron заявляет о задержке менее 1 мс при 99,9999 % операций. 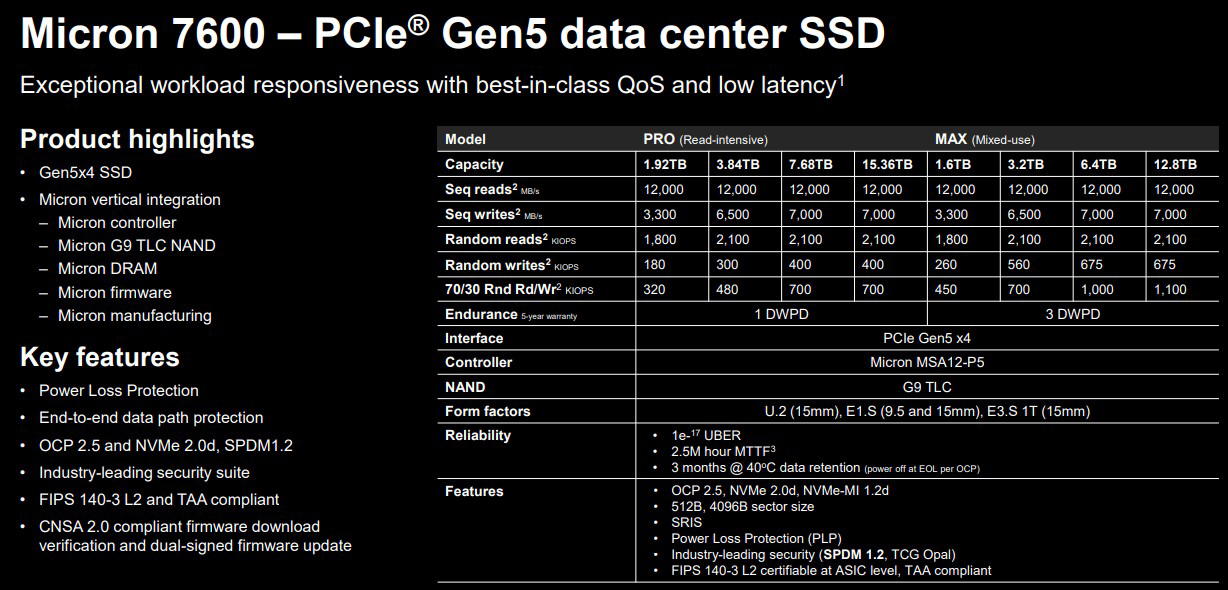 Изделия Micron 9650 специально разработаны для обучения ИИ-моделей, инференса в режиме реального времени и других задач, при которых критическое значение имеют производительность и стабильная пропускная способность. Устройства в форм-факторах E3.S и E1.S оснащены интерфейсом PCIe 6.0 х4 (NVMe 2.0). Используются чипы флеш-памяти G9 TLC NAND. Максимальная скорость последовательного чтения заявлена на уровне 28 000 Мбайт/с, последовательной записи — 14 000 Мбайт/с. Устройства E1.S допускают применение жидкостного охлаждения. 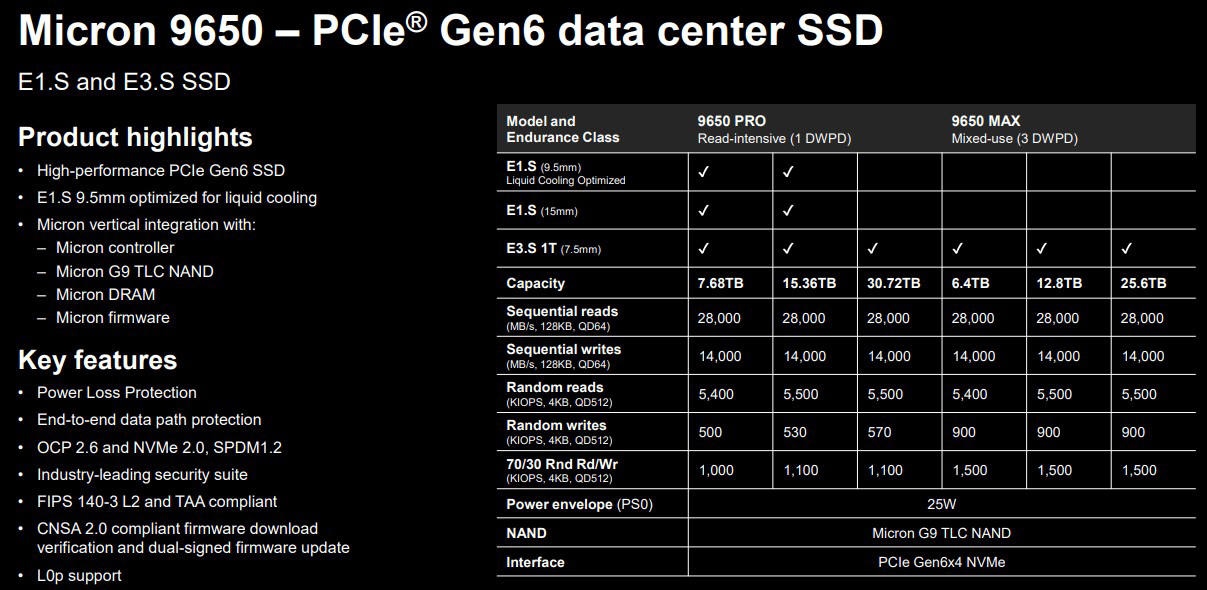 Серия включает версии Micron 9650 Pro (1 DWPD) и Micron 9650 Max (3 DWPD) вместимостью 7,68–30,72 и 6,4–25,6 Тбайт соответственно. Показатель IOPS при произвольном чтении достигает 5,5 млн, при произвольной записи — 1,1 млн у Pro и 1,5 млн у Max. Максимальное энергопотребление у всех представленных изделий находится на уровне 25 Вт. Средняя наработка на отказ (MTTF) — 2,5 млн часов при температуре до +50 °C. Пробные поставки устройств Micron 7600 и Micron 9650 уже начались, а SSD серии Micron 6600 ION выйдут позднее в текущем квартале.
29.07.2025 [16:38], Сергей Карасёв
MaxLinear представила DPU Panther V с пропускной способностью 450 Гбит/сКомпания MaxLinear анонсировала ускоритель обработки данных Panther V, предназначенный для использования в дата-центрах и инфраструктурах гиперскейлеров. Решение берёт на себя выполнение таких ресурсоёмких операций с данными, как сжатие, дедупликация, шифрование и проверка в реальном времени. В результате, снижается нагрузка на CPU, уменьшаются задержки, повышаются общая производительность и энергоэффективность, а также сокращаются капитальные и эксплуатационные затраты. Новинка выполнена на той же архитектуре, которая лежит в основе DPU Panther III. При этом вместо интерфейса PCIe 4.0 используется PCIe 5.0 (x16). Пропускная способность увеличена более чем в два раза — с 200 до 450 Гбит/с. Устройство оптимизировано для НРС-задач, гипермасштабируемых и гиперконвергентных архитектур, рабочих нагрузок ИИ и машинного обучения. 
Источник изображения: MaxLinear Упомянут механизм дедупликации структурированных данных MaxHash вплоть до 15:1 (в сочетании с алгоритмами глубокого сжатия). Это значительно повышает эффективную вместимость и увеличивает срок службы NVMe SSD. Реализованы различные средства обеспечения безопасности, включая сквозную защиту данных, ЕСС и пр. Говорится о развитой программной экосистеме: это SDK с унифицированными API, а также интеллектуальный балансировщик нагрузки для бесшовной интеграции в средах Linux и FreeBSD. Возможно объединение в системе нескольких ускорителей Panther V с суммарной пропускной способностью свыше 3,2 Тбит/с.
22.07.2025 [11:07], Сергей Карасёв
Kioxia представила первый в мире NVMe SSD вместимостью 245 ТбайтКомпания Kioxia анонсировала первый в отрасли твердотельный накопитель NVMe, способный вместить 245,76 Тбайт информации. Устройство, вошедшее в семейство LC9, рассчитано прежде всего на рабочие нагрузки, связанные с генеративным ИИ. SSD серии LC9 дебютировали в марте нынешнего года. Их основой служат чипы флеш-памяти BiCS FLASH QLC 3D с технологией CBA (CMOS directly Bonded to Array). Задействован неназванный проприетарный контроллер, совместимый с NVMe 2.0. Для обмена данными используется интерфейс PCIe 5.0 x4 (с поддержкой двух портов). Изначально в семействе LC9 были представлены решения в формате U.2 вместимостью до 122,88 Тбайт. Теперь максимальная ёмкость таких устройств увеличилась в два раза — до 245,76 Тбайт. Кроме того, в серии LC9 появились изделия типоразмера EDSFF E3.L на 245,76 Тбайт, а также EDSFF E3.S на 122,88 Тбайт. 
Источник изображения: Kioxia Скорость последовательного чтения достигает 12 Гбайт/с, скорость последовательной записи — 3 Гбайт/с. Это не самые высокие показатели для SSD корпоративного класса с интерфейсом PCIe 5.0, но в данном случае Kioxia пришлось пойти на компромисс с целью достижения рекордной вместимости. Величина IOPS на операциях произвольного чтения составляет до 1,3 млн IOPS, на операциях произвольной записи — до 50 тыс. Накопители рассчитаны на 0,3 полных перезаписи в сутки (показатель DWPD). SSD поддерживают ряд функций для повышения надёжности и обеспечения целостности данных. Это средства защиты от внезапного отключения питания (PLP), технология FDP (Flexible Data Placement) для повышения долговечности, инструмент управления ошибками на основе контроля четности и пр. Реализованы шифрование AES-256 и алгоритмы постквантовой криптографии, устойчивые к атакам будущих квантовых компьютеров. |
|

